Vault 集成存储(Integrated Storage)
Vault 支持多种存储选项,用于存储 Vault 的持久化信息。从 Vault 1.4 开始,提供了一个集成存储选项。该存储后端不依赖任何第三方系统,实现高可用性语义,支持企业版复制功能,并提供备份/恢复工作流。
集成存储将 Vault 的数据存储在 Vault 服务器的文件系统上,并使用共识协议将数据复制到集群中的每个服务器。
本节以下部分将详细介绍如何操作 Vault 集成存储。
服务器对服务器通信
一旦节点相互组成集群,它们就开始通过 Vault 的集群端口进行 mTLS 协议通信。集群端口默认为 8201。TLS 信息在加入时交换并定期轮替。
使用集成存储的一个必要条件是已经设置了 cluster_addr 配置。这使得 Vault 在加入集群时会为节点 ID 分配一个地址。
集群成员
本节将概述如何启动和管理一个使用集成存储的 Vault 集群。
集成存储在节点执行 vault operator init 命令的过程中被启动,先组成一个尺寸为 1 的集群。根据所需的部署尺寸,其他节点可以加入到某个已经有主节点的集群成为备用节点。
加入集群
加入集群是初始化一个 Vault 节点并使其成为某个已有集群的成员的过程。为了向集群验证新节点,它必须使用相同的封印机制。如果使用自动解封,则必须将节点配置为使用与其尝试加入的集群相同的 KMS 提供程序和密钥。如果使用 Shamir 封印,则必须在加入过程完成之前将解封密钥提供给新节点。一旦一个节点成功加入,来自主节点的数据就可以向它开始复制。一旦节点加入了一个集群,就不能重新加入不同的集群。
您可以通过配置文件自动加入节点,也可以通过 API 手动加入节点(两种方法在下文叙述)。加入节点时,必须使用 leader 节点的 API 地址。建议在所有节点上设置 api_addr 配置以使加入集群变得更简单。
retry_join 配置
该方法允许在配置文件中设置一个或多个目标领导节点。当一个尚未初始化的 Vault 服务器启动时,它将尝试加入每个定义的潜在领导者的集群,重试直到成功。当指定的领导者之一变为主节点时,该节点即可成功加入集群。节点使用 Shamir 封印时,新加入的节点仍然需要手动解封。使用自动解封时,节点可以自动加入和解封。
下面是一个使用 retry_join 配置的例子:
storage "raft" {
path = "/var/raft/"
node_id = "node3"
retry_join {
leader_api_addr = "https://node1.vault.local:8200"
}
retry_join {
leader_api_addr = "https://node2.vault.local:8200"
}
}
注意,在每个 retry_join 节中,您可以提供一个 leader_api_addr 或 auto_join 值。当提供了一个云平台对应的 auto_join 配置值时,Vault 将使用 go-discover 库尝试自动发现和解析潜在的 Raft 主节点地址。
请查阅 go-discover 的说明文档了解有关 auto-join 值的详细信息。
storage "raft" {
path = "/var/raft/"
node_id = "node3"
retry_join {
auto_join = "provider=aws region=eu-west-1 tag_key=vault tag_value=... access_key_id=... secret_access_key=..."
}
}
默认情况下,Vault 将尝试使用 HTTPS 和 8200 端口来访问被发现的节点。操作员可以通过设置 auto_join_scheme 和 auto_join_port 字段覆盖这两个配置。
storage "raft" {
path = "/var/raft/"
node_id = "node3"
retry_join {
auto_join = "provider=aws region=eu-west-1 tag_key=vault tag_value=... access_key_id=... secret_access_key=..."
auto_join_scheme = "http"
auto_join_port = 8201
}
}
通过命令行加入集群
我们可以使用命令行工具的 join 命令或者调用 API 来加入集群。需要指定属于主节点的 API 地址:
$ vault operator raft join https://node1.vault.local:8200
从集群中移除节点
当不再需要集群中的某个节点时,需要将其从集群中删除。这可能发生在将一个节点替换为另一个新的节点、节点主机名发生永久性的变更并且无法再被访问、又或者试图缩小集群尺寸等等许多原因时。从集群中删除节点要先确保集群在删除后能够保持所需的最小尺寸,并保持足以形成多数。
可以通过 remove-peer 命令从集群中删除特定节点:
$ vault operator raft remove-peer node1
Peer removed successfully!
枚举节点
可以通过 list-peers 命令查询集群中目前存在的节点。所有投票节点都会被列出,为保持集成存储集群的正常运行,集群中的过半多数必须保持在线。
$ vault operator raft list-peers
Node Address State Voter
---- ------- ----- -----
node1 node1.vault.local:8201 follower true
node2 node2.vault.local:8201 follower true
node3 node3.vault.local:8201 leader true
集成存储和 TLS
我们在上面关于引导启动集群的部分中略过了一些细节。对于大多数情况来说上面的说明已经足够了,但是一些用户在使用自动加入集群和 TLS 功能与其他功能例如自动缩放等结合使用时会遇到一些问题。问题是 go-discover 插件在大多数平台上返回的是 IP(而不是主机名),并且这些 IP 是无法提前预知的,导致用于保护 Vault API 端口的 TLS 证书在其 IP SANs 中无法包含这些 IP。
回顾 Vault 的组网
在我们继续探索这些问题的解决方案之前,我们要先回顾一下 Vault 节点之间如何相互交流。
Vault 暴露两个 TCP 端口: API 端口(api_addr)和集群端口(cluster_addr)。
API 端口是接受客户端发给 Vault 服务的 HTTP 请求的端口。
对于单节点 Vault 集群,不需要考虑集群端口,因为它不会被使用。
当部署多个节点时,我们还需要一个集群端口。 Vault 节点使用它来向彼此发出 RPC 调用,例如将客户端发送的请求从备用节点转发到主节点,或者在使用 Raft 协议时,处理领导者选举和存储数据的复制。
集群端口使用 Vault 主节点在其内部生成的 TLS 证书进行保护。在不使用集成存储时(也就是集群节点之间使用共享存储时)它的工作原理很简单:每个节点至少有对存储的读访问权限,因此一旦主节点保存了证书,备用节点就可以获取到该证书,并且就如何加密集群流量达成一致。
启用集成存储时过程就比较复杂了,因为存在先有鸡还是先有蛋的问题。为了交换证书来组建 Raft 集群,我们需要启用存储数据的复制;但是在组成 Raft 集群之前,节点间又无法安全地复制数据!为了解决这个问题,一个 Vault 节点必须使用 API 端口而不是集群端口与另一个 Vault 节点通话。这是目前开源版 Vault 执行这种操作的唯一情况(Vault 企业版在配置复制时也会执行类似操作。)
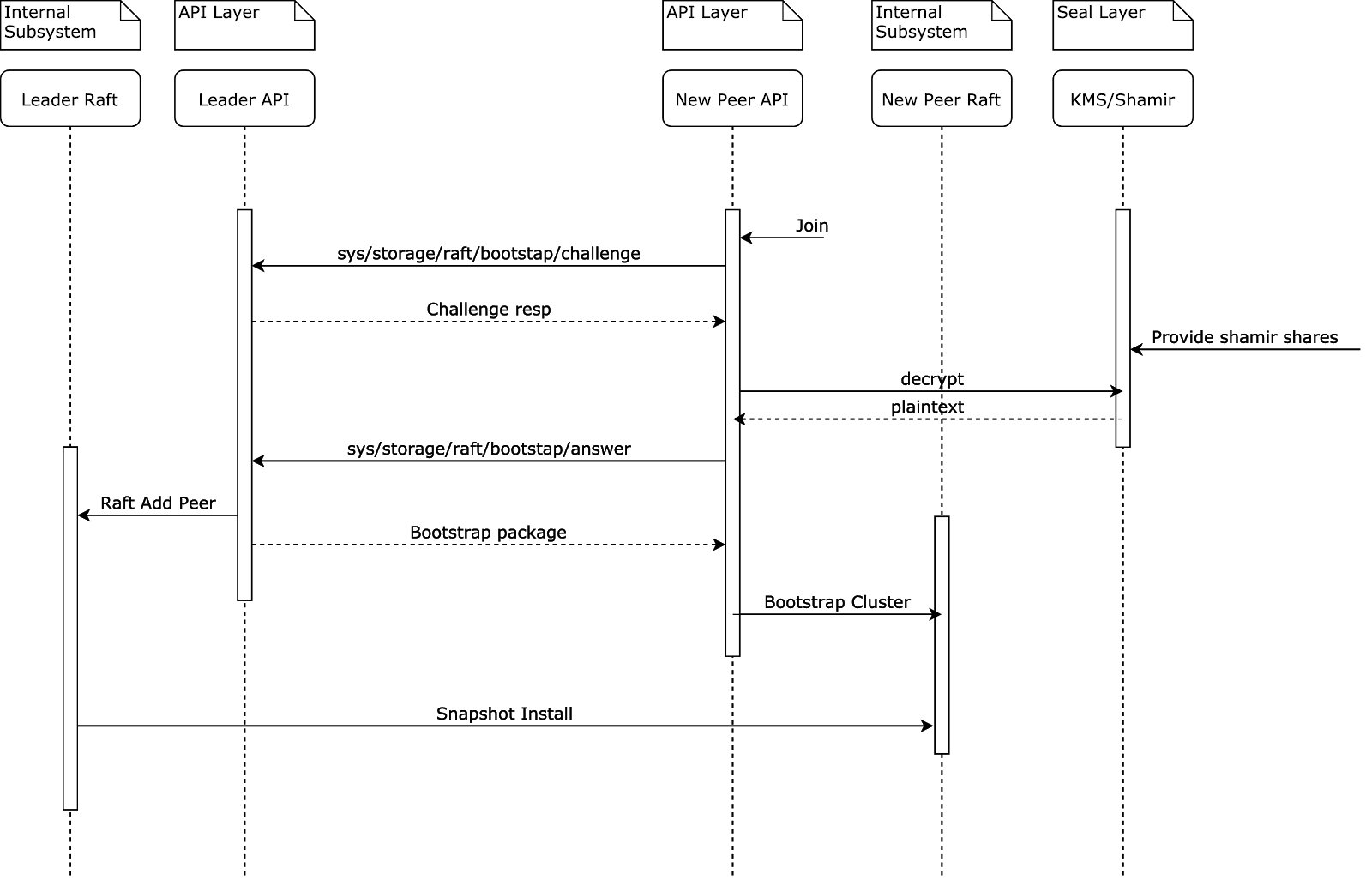
node2想要加入集群,于是调用了已经加入集群的成员node1的 challenge APInode1收到 challenge 请求后返回 (1) 一个加密的随机 UUID (2) 封印配置node2必须使用收到的封印配置来解密收到的 UUID;如果节点使用自动解封那么可以直接解密。如果使用的是 Shamir,那么必须等待用户提供足够多的解封密钥来完成解密。node2将解密后的 UUID 通过 answer API 回复给node1node1验证后认定node2可以信任(因为它证明它可以处理封印),然后返回一个引导启动包,包含了集群 TLS 证书以及私钥node2通过集群端口读取一份 Raft 快照
经过这个步骤后,新加入的节点将用不再发送任何请求到 API 端口。所有后续的节点间通信流量都将被发送到集群端口上。
辅助加入 Raft 的技术
最简单的办法就是使用 raft join 命令,显式给定要加入的集群的节点名字或是 IP。在本节中我们将了解其他更适合自动化的兼容 TLS 的选项。
使用 TLS servername 的自动加入
从 Vault 1.6.2 开始,加入集群最简单的方式就是在 retry_join 节中指定 leader_tls_servername,内容要匹配证书中的 DNS SAN。
请注意,证书的 DNS SAN 中的名称实际上不需要实际在 DNS 服务中注册。节点可能在 DNS 中查不到对应名称,但仍在使用在 DNS SAN 中包含此共享的 servername 值的证书。
为自动加入添加 CIDR 限制,在证书中列举所有可能的 IP
如果所有 Vault 节点 IP 都是从一个小子网分配的,例如 /28,将存在于该子网中的所有 IP 放入节点将要共享的 TLS 证书的 IP SAN 中就变得切实可行起来了。
该方案的缺点是集群尺寸可能有一天会超过现在的 CIDR 限制,更改 CIDR 可能会很困难。出于类似的原因,当要使用非投票节点和动态集群伸缩功能时,该解决方案可能不切实际。
使用负载均衡器取代自动加入
大多数 Vault 实例会通过负载均衡器与客户端连接。如果是这样,那么负载均衡器知道如何将流量转发到处于工作状态的 Vault 节点上,这样就不需要使用自动加入了。我们可以把 retry_join 设置成负载均衡器的地址。
一个潜在的问题:一些用户想要一个面向公网的负载均衡器,使得客户端可以连接到 Vault,但同时对从 Vault 节点流出 Vpc 到负载均衡器的公网地址的流量感到担忧。
灾难恢复
集群多数仍在的情况
本节概述了当单个服务器或多个服务器处于故障状态,但集群多数节点仍然维持工作时要采取的步骤。这时剩余的活动服务器仍然可以运行,可以选举领导者,并且能够处理写入请求。
如果发生故障的服务器是可恢复的,最好的选择是将其重新联机并使其重新连接到具有相同主机地址的集群。这将使集群恢复到完全健康的状态。
如果这无法实现,那么就需要删除出现故障的服务器。通常,我们可以使用 remove-peer 命令来删除那些仍然在集群中的故障服务器。
如果无法使用 remove-peer 命令,或者我们更希望手动调整集群成员名单,则可以向配置的数据目录写入一个 raft/peers.json 文件。
集群多数离线的情况
如果多台服务器离线,导致集群多数节点丢失,服务完全中断,部分的恢复仍然是可能的。
如果发生故障的服务器是可恢复的,最好的选择是让它们重新联机并使用相同的主机地址重新连接到集群。这将使集群恢复到完全健康的状态。
如果发生故障的服务器无法恢复,则可以使用集群中其余服务器上的数据进行部分恢复。在这种情况下可能会丢失数据,因为丢失了多数的服务器,因此有关已提交内容的记录可能不完整。恢复过程会隐式提交所有未完成的 Raft 日志条目,因此也可以提交一些在故障前尚未提交的数据。
可以阅读下面通过 peers.json 文件手工恢复集群的内容来获取详细的恢复步骤。我们只在 peers.json 文件中添加还在运行的节点。集群中剩余节点在配置了一致的 peers.json 文件并进行重启后应该就可以重新选举出新的领导者节点。
后续添加的新节点都是全新的没有任何数据的,需要用 Vault 的加入集群命令来添加到集群中。
极端情况下,可以通过在某一台服务器中配置一个只有它自己的 peers.json 恢复文件来将其回程一个单台节点构成的集群。
手动使用 peers.json 文件恢复
使用 raft/peers.json 文件进行恢复可能会导致未提交的 Raft 日志条目被意外提交,因此只有在没有其他选项可用于恢复丢失服务器所引发的服务中断时才可以使用这个方法。请确保没有任何定期新增该文件的自动化流程在运行。
第一步,停止所有剩余的服务器。
下一步是转到每个 Vault 服务器配置的数据路径。在该目录中,会有一个 raft/ 子目录。我们需要创建一个 raft/peers.json 文件。该文件的格式为 JSON 数组,数组中包含我们希望加入到集群的每个 Vault 服务器的节点 ID、地址:端口和选举权信息:
[
{
"id": "node1",
"address": "node1.vault.local:8201",
"non_voter": false
},
{
"id": "node2",
"address": "node2.vault.local:8201",
"non_voter": false
},
{
"id": "node3",
"address": "node3.vault.local:8201",
"non_voter": false
}
]
id``(string: <required>)——指定服务器的节点 ID。我们可以在配置文件中找到它,或者如果它是自动生成的,则可以在服务器数据目录中的node-id文件中找到。address``(string: <required>)——指定服务器的主机和端口。该端口是服务器的集群端口。non_voter``(bool: <false>)——该选项表示该服务器是否是无投票权。如果忽略,它将默认为false,大多数集群都使用false,这是企业版独有的功能。
为所有剩余的服务器编写相应的条目。我们必须要确定此文件未包含的服务器确实发生了无法恢复的故障,并且以后不会重新加入集群。另外要确保此文件在所有其余服务器节点上都是一样的。
这时,我们可以重新启动所有剩余的服务器。集群应该能够恢复到工作状态。其中一个节点应该被选举为领导节点并成为主节点。
其他恢复方法
对于不涉及 Raft 的恢复方法我们将在其他章节中加以介绍。